两倍效能升、同样价格售,NVIDIA 新世代 “Ampere” 游戏显示卡可说是相当兇狠,两倍 FP32 核心、第二代 RT Core 与第三代 Tensor Core 更新,再加上 NVIDIA 的推波助澜之下,让下半年 AAA 大作纷纷挂上 RTX On 的招牌,而究竟这代效能提升了多少,是否能解 4K60fps 的美梦,光追 AI 游戏效能又是如何呢!最后,这代该升级吗?

首发 RTX 3080、9/24 卡皇 RTX 3090 以及杀手 RTX 3070
9/16 解禁、9/17 首发上市的则是 NVIDIA GeForce RTX 3080 显示卡,而这代卡皇 BFGPU GeForce RTX 3090 则是 9/24 号上市,至于这代最佳甜蜜代表(性价好)的 RTX 3070 则要等待 10 月 15 日上市。
首先新一代 Ampere 架构显示卡,由于 FP32 单元翻倍,因此 CUDA 核心翻倍成长,除此之外也同时升级了第二代 RT Core 与第三代 Tensor Core 核心。
首发 RTX 3080 採用 GA102 GPU,分为 6 组 GPC 单元与共 68 组 SM 单元,CUDA 核心则达到 8704 个,第二代 RT Core 68 个、第三代 Tensor Core 272 个,而 Texture / ROP Units 也都有着升级,整体规格对比上代 RTX 2080 有着明显提升,但这代创始版 GPU Boost 时脉相对较低 1710 MHz;此外,RTX 3080 也升级 10GB GDDR6X 记忆体,有着更高的记忆体频宽与传输性能
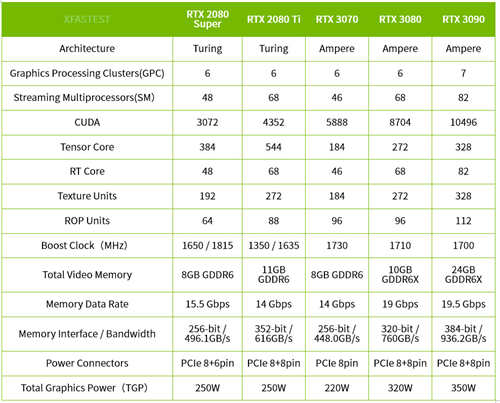
↑ RTX 3090、RTX 3080 与 RTX 3070 规格表。
至于 RTX 3070 在 CUDA 核心数量已超过 RTX 2080 Ti,而最终效能如何则要等待 10 月揭晓;BFGPU RTX 3090 则是採用完整的 A102 核心,CUDA 数量高达 10496 个,并有着夸张 24GB GDDR6X 记忆体配置。
这也是为何这代显示卡,能被玩家所期待,规格效能倍增、价格不变。

↑ RTX 3090、RTX 3080 与 RTX 3070 台湾建议售价。
简单暴力 Ampere 架构更新重点:FP32 快取翻倍
Ampere 的 Streaming Multiprocessors(SM)单元,内含着 16 FP32 运算单元,以及另外 16 个可运算 FP32 或 INT32 的混合运算单元,因此一个时脉週期可执行最高 32 FP32 运算,或者是 16 FP32 加上 16 INT32 的运算,而 4 个 SM 分区达到 128 FP32 运算/clock,相较于 Turing 世代则是 2 倍的运算量提升。
随着 CUDA 运算单元的数量倍增,SM 也加倍 L1 快取频宽、33% 快取容量提升与 2 倍快取分区大小;而每个 SM 当中也包含 1 个 RT Core 核心,可有着 2 倍 Triangle Intersection 速率提升与 4 个 Tensor Core 核心,有着 2 倍稀疏矩阵运算能力。
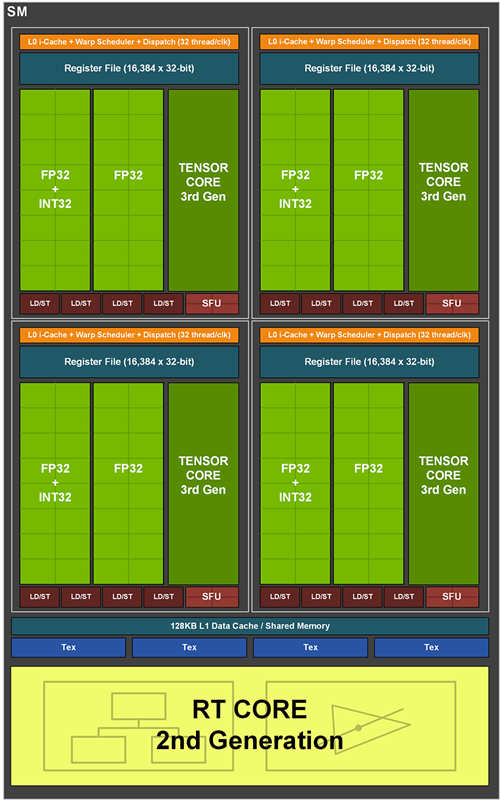
↑ Ampere 的 Streaming Multiprocessors(SM)单元。
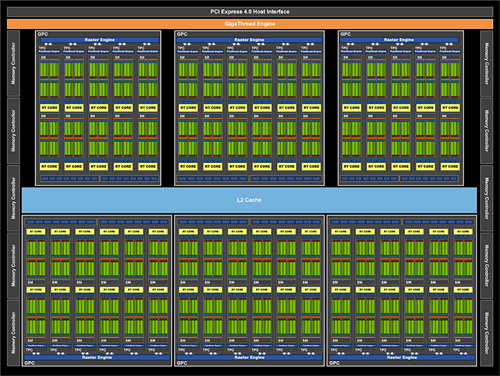
↑ RTX 3080 的 GA102 GPU 核心区块图。
第二代 RT Core 与第三代 Tensor Core 更新
第二代 RT Core 同样针对「Bounding Volume Hierarchy(BVH)」演算法进行加速,通过硬体加速 Bbox intersection 与 Triangle intersection 的处理速度,并导入「Motion Blur」硬体加速功能,也就是在 Bbox 与 Triangle intersection 寻找当中,导入 Interpolate tri position(时间)的参数,让光线追蹤时可根据时间来变化,最终可渲染出具备动态模糊的光线追蹤影像,并让以往动态模糊光线追蹤效能达到 8x 快的 Ray Traversal。

↑ 第二代 RT Core 导入 Motion Blur 光线追蹤技术。
第三代 Tensor Core 当中採用「Sparse Deep Learning」技术,将以往的稠密矩阵转化为稀疏矩阵,并分配给 Tensor Core 核心计算,并针对 Sparsity Optimized 优化核心,也因此这代 GA100(A100)与 GA102(RTX 3080)的 SM 单元 Tensor Core 数量降至 4 个核心(TU102 SM 为 8)。
在 Tensor Core 数量降低的状况下,即便是以往 Dense 实作 GA102(RTX 3080)也有着 128 FP16 FMA 的速度,比起上一代 RTX 2080S 仅 64 FP16 FMA,而当使用 Sparse 算法则可达到 2 倍的运算速度提升。

↑ 第三代 Tensor Core 优化 Sparse Deep Learning。
GDDR6X 记忆体、HDMI 2.1 输出、AV1 硬体解码
两张高阶的 GeForce RTX 3080 与 RTX 3090,纷纷採用 GDDR6X 记忆体,使用四位準脉波振幅调变(four-level pulse amplitude modulation, PAM4),实现 GDDR6X 的突破性频宽;在一个 250mV 的电压 Steps 当中,採用 4-level PAM4 调变来乘载资料。
并为了达到最高传输效能,通过 Max Transition Avoidance Coding 确保「眼图」能够有明确的讯号,而根据不同板子等设计,採用新演算法 Training and Adaptation 找到最适合的取样点。

↑ GDDR6X 记忆体。
RTX 30 世代都将升级 HDMI 2.1 规格,将能够一线点亮 8K60Hz 或 4K120Hz 的显示规格,并且支援 Display Stream Compression 1.2a(DSC)可点亮 HDR 影像,此外还支援着 Variable Refresh Rate 的可变更新率。
这意味着未来 NVIDIA G-Sync(相容)有可能导入 HDMI 2.1 连接埠,让 HDMI 用户也可点亮 G-Sync 同步的能力,但目前 NVIDIA 并未针对未来功能多做说明。
另一方面,GPU 的影像解码则加入 AV1 解码支援,而编码功能则与 RTX 20 系列 GPU 相同。

↑ 8K、HDMI 2.1 与 AV1 解码。
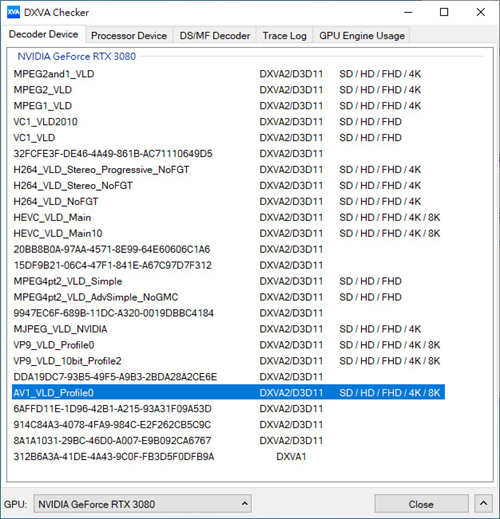
↑ AV1 解码规格,已在 DXVA Check 中检视。
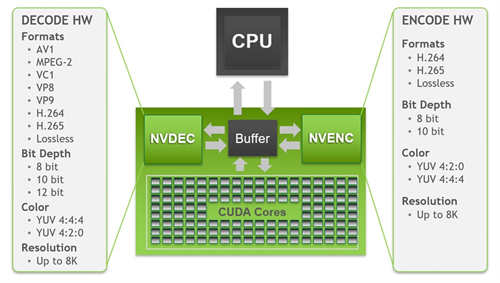
↑ Ampere NVDEC。
NVIDIA GeForce RTX 3080 创始版开箱 / 紧凑 PCB 正反双扇 颠覆以往
这一代 NVIDIA 创始版显示卡,可说是有着颠覆以往显卡印象的新颖设计,历代视为信仰的 GEFORCE RTX 招牌改为白色灯光,并採用着 X 形状的一体式框架,搭配均温板複合热导管和散热鳍片,通过正反 8.7mm 轴向式进风、抽风配置,打造全新的显卡散热设计。

↑ NVIDIA GeForce RTX 3080 创始版外盒。

↑ 这代显卡稳稳的斜躺于包装之内。
这代最容易让人混淆的就是,创始版将以往的显卡背面设计改为正面,露出 X 框架的线条,高质感雾黑的背板,上头印着 RTX 3080 的字样,以及背面的轴向式抽风扇。
而以往的显卡正面,则是同样展露 X 框架,并全面改以散热鳍片,通过热导管将废热引导至显卡前端,提升整体的散热效果,也可带动机壳内部的气流。

↑ RTX 3080 正面美照。

↑ RTX 3080 背面,X 框架与满满的散热鳍片。
缩小电路板、改造散热器之后,这代 RTX 3080 创始版,尺寸来到 285 x 112 mm、2 Slot 插槽设计,换句话说比起上一代 RTX 20 创始版还要长了 2cm;此外,显卡重量也来到 1.385kg,比起上一代重了 122g。
此外,因为电路板缩小并改用 PCIe 12-pin 供电接头,使得出线处位于显卡的中段,若在加上转接线之后,这出线位置势必让理线魔人心烦,这也只能透过日后客製线来美化了。

↑ 显卡侧面,GEFORCE RTX 字样,以及 PCIe 12-pin 供电接头。

↑ 这代显卡较长 28.5cm。

↑ 高度同样是 2 Slot 佔用。
RTX 3080 创始版同样提供 4 影像输出,分别为 HDMI 2.1 与 3 个 DisplayPort 1.4a 连接埠,新的 HDMI 2.1 支援到 4K120Hz 与 8K60Hz 输出,连接线频宽达到 4 线共 48Gbps,并支援 Variable Refresh Rate 功能。
但未来 G-Sync 萤幕是否开放 HDMI 2.1 支援,这点就要看 NVIDIA 的规划了。

↑ 影像输出埠。
配件中包含产品的说明文件,以及相当重要的 PCIe 12-pin 转 2 个 PCIe 8-pin 的转接线,NVIDIA 建议使用原厂线材,除非客製端明确了解接头配置,否则将会影响到产品保固。

↑ 创始版配件。

↑ PCIe 12-pin 转 2 个 PCIe 8-pin 的转接线。
这代创始版因为电路板缩小,使用螺丝的数量也有减少,但拆解还是有些小细节要注意,例如正面的螺丝孔,採用磁铁盖遮住,还有 V 形的开口下也藏着螺丝。
鬆开螺丝后取下背板,可见新的创始版散热器,其 GPU 后方加入 X支架,提升散热器压合的力道。

↑ 隐藏螺丝设计。

↑ GPU 採用 X 支架提升散热器的压合力道。
拆解下电路板之后,主要分为散热器本体、电路板、背板。

↑ 创始版拆解。
缩小电路板面积,可将发热元件集中,让散热器均温板可直接覆盖;但由于 RTX 3080 採用 GDDR6X 记忆体,相对在布线、PCB 板层上更要求讯号品质。
GPU 型号为 GA102-200-KD-A1,周围有着 10 颗 GDDR6X 记忆体,组成 10GB 记忆体容量,供电项则相当豪华,提供这张 320W TGP 的供电。

↑ 缩小电路板,右侧 V 字开孔刚好迎合风扇。

↑ GA102-200-KD-A1 GPU。

↑ 由于 12-pin 接头有转角设计,因此后方的线路更粗更厚。
这代散热器则是均温板接触 GPU,并替周围的记忆体、供电项进行散热,并複合 4 根热导管与散热鳍片,搭配两颗风扇带来更好的散热效果。

↑ 散热器替 GPU、记忆体与供电元件散热。

↑ 这代创始版唯读白色灯光的 LED。

↑ X 金属框架。
创始版上机效果,主要在显卡下方的两个 V 字有着白色灯光,而侧面的 GeForce RTX 也有着白色灯光,这代不点亮 NVIDIA 招牌绿色,改为白灯、黑卡与钛金色的金属外框,整体质感更胜以往。

↑ RTX 3080 创始版上机照。

↑ RTX 3080 创始版上机照。

↑ RTX 3080 创始版上机照。
NVIDIA GeForce RTX 3080 性能测试 / 影像输出、3D 渲染
本次测试报告,除 NVIDIA GeForce RTX 3080 创始版之外,也準备上一代同阶 RTX 2080 Super 创始版,以及 RTX 2080 Ti 创始版做为比较之用;测试平台,则使用 Intel Core i9-10900K、ASUS ROG MAXIMUS XII EXTREME 与双通道 DDR4 16GB-3600 记忆体。
至于目前 PCIe 4.0 对于显示卡效能上差异不大,除非明年 RTX IO、DirectStorage 导入之际,才有机会见到新 API 发挥出 PCIe 4.0 高频宽与 SSD 的实际 I/O 性能。

↑ RTX 3080 对上 RTX 2080 Super 与 RTX 2080 Ti。
测试平台
处理器:Intel Core i9-10900K
主机板:ASUS ROG MAXIMUS XII EXTREME
记忆体:G.SKILL DDR4 8GB*2-3600
显示卡:NVIDIA GeForce RTX 3080
系统碟:Samsung NVMe SSD 960 PRO M.2
电源供应器:Phanteks REVOLT PRO 1000W
作业系统:Windows 10 Pro 1909 64bit
首先 GPU-Z 已可检视 NVIDIA GeForce RTX 3080 资讯,採用 8nm 製程的 GA102 GPU,有着 8704 个渲染 CUDA 核心,以及 10240 MB GDDR6X(Micron)记忆体,而 GPU 预设时脉 1440 MHz、Boost 1710 MHz。

↑ GPU-Z。
随着 Adobe Premiere Pro 2020 终于支援 CPU + GPU 混合运算,通过 Mercury Playback Engine GPU 加速,编辑时的特效回放速度,此外 NVIDA NVENC 则可加速影像输出时,H.264 与 HEVC(H.265)影像编码。
测试影片专案说明如下:
公司拍摄的 1080p60 开箱影片,基本剪辑、音轨、字幕,无任何特效。FinalAdjusted_MPE 则是剪辑过的音乐影片,来源为 2160p24fps,特效使用:Scaled video, luma curve adjustment, fast blur, noise, tint, RGB curves, black & white effect, image blending, video overlay。IntroSequence 4K 为模仿影片开头的开场画面,使用两个影像包含色彩方块与线条以及文字层,套用 Lens 特效。BigMix 则使用了 3 段 FinalAdjusted_MPE 1920x1080 的影像组成一段 4K 时间轴。
首先一般影片剪辑的公司影片,老实说通过 GPU 加速后,确实比单靠 CPU 运算快上许多,但因为套用的特效不多,因此效能提升并不明显。
而 NVIDIA 提供的专案,则可感受到因套用特效较多的情况下,PR 藉由硬体加速的方式,带来更快的影片输出加速;从结果来看 RTX 3080 藉由 GPU 加速,影像输出效能对比 RTX 2080 Super 提升 23%、对比 RTX 2080 Ti 增加 10%。
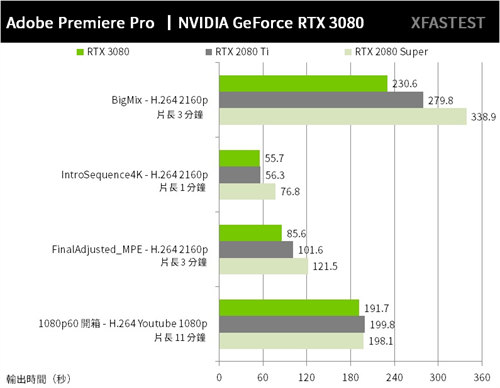
↑ Premiere Pro 影片输出时间,秒速越短越好。
Da Vinci Resolve 纯粹通过 GPU 加速的影片剪辑程式,更包含强大的色彩校正与特效功能,并且直接使用 CUDA 核心运算,让影片剪辑的回放与输出都有着相当好的性能。
测试影片专案由 NVIDIA 提供,说明如下:
Wedding_Heavy_Styles 第一个片段,节点 1 OFX: Light Rays、节点 2 gaussian blur with a mask、节点 3 second gaussian blur and a OFX Glow、节点 4 OFX: Styles effect,第二个片段第一节点 pass-through node、第二节点 gaussian blur with mask、第三节点 OFX: Light Rays with a mask、第四节点 primary color correction and a curves adjustment,最后使用 OFX: Sketch effect。Bride_FaceRefine_Selective Color 则是通过 Face Refinement node 进行脸部优化,并通过 Resolves Neural Engine 追蹤主角脸部并将背景灰阶处理,节点 1 Face Refinement、节点 2 Beauty node、节点 3 OFX: Glow, primary balance, Custom Curves, Hue vs Sat Curve, Power Windows, Tracking and External Key、节点 4 Primary Balance, RGB Mixer, Custom Curves, Hue vs Sat Curve, Power Windows, Tracking, External Key and OFX: Gaussian Blur。50% Retime 则是将第二只影片套用 Optical Flow with SpeedWarp AI 慢速播放。SuperScale 2x 4KSource 使用 4K ProRES 影片,以及 Super Scale 至 2x Zoom in 的 4K 输出影片。SuperScale 4x HD_Source 使用 HD H.264 影片,以及 Resolve’s Super Scale 将影片提升至 4K 影片输出。
从结果来看,RTX 3080 输出效能比起 RTX 2080 Super 快上 49%,对比 RTX 2080 Ti 则是有着 28% 的效能增长;若是 Resolve 的用户,这效能提升与同样价格比较之下,是否有心动呢!
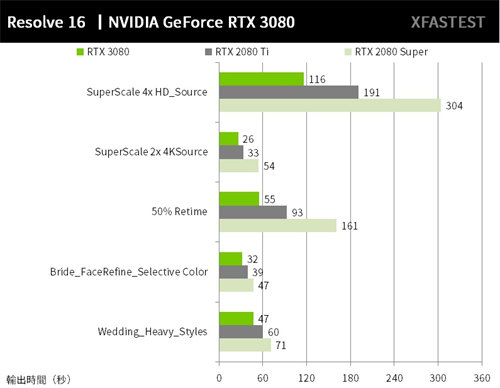
↑ Resolve 影片输出时间,秒速越短越好。
Blender 是跨平台、开放源码的 3D 创作工具,支援着 CPU 与 GPU 的渲染加速功能,以及各种 3D 作业:Modeling、Rigging、Animation、Simulation、Rendering、Compositing 与 Motion Tracking 等。
通过 Blender Benchmark 2.9 测试,Blender 的各式渲染 bmw27、classrom、koro 等,都可感受到 RTX 3080 的速度提升,对比上代 RTX 2080 Super 有着平均 50% 效能提升、对比 RTX 2080 Ti 则是 38%。

↑ Blender,时间越短越好。
V-Ray Benchmark 是由 Chaos Group 所开发,V-Ray 是基于物理法则所设计的光线渲染软体,而此工具可针对 CPU 进行光线追蹤的渲染图像的运算效能测试,GPU测试以 mpaths 为单位。
RTX 3080 可达到 627 mpaths 的效能,对比 RTX 3080 有着近乎倍增的 132% 效能提升,对比 RTX 2080 Ti 则是 79% 提升。
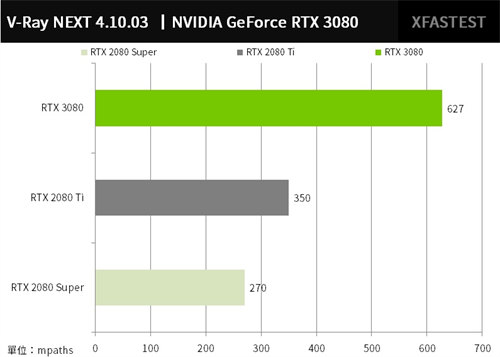
↑ V-Ray Benchmark,性能越高越好。
小结,对于影像输出、GPU 渲染等工作,RTX 3080 的效能提升相当明显,就看各位要不要升级缩短输出时间啰!
NVIDIA GeForce RTX 3080 效能跑分测试
RTX 3080 本业还是在游戏显卡,先通过 3DMark 测试衡量三彰显卡的基本效能。
首先主流的 1080p 解析度 Fire Strike 测试,RTX 3080 获得 31,056 分,而 1440p 的 Extreme则有 19,656 分,更高 4K 2160p 解析度的 Ultra 测试则获得 10,730 分的成绩。
这可以说是首次 Fire Strike Ultra 单卡就可达到破万分的总成绩,而对比效能提升百分比,这段测试就不能取平均来检视了。
RTX 3080 确实在 1080p 解析度的 Fire Strike 测试性能提升不多,但这不是他的错,是 1080p 所需的效能就是如此,但是在 1440p 与 2160p 的测试,RTX 3080 性能比起 RTX 2080 Super 可都有着 60% 以上的性能提升,对比 RTX 2080 Ti 则是在 23%、30% 左右。
换句话说使用 DirectX 11 API 的游戏,在 1080p 升级确实不大,但当解析度提升这效能增长还是显着。
RTX 3080 效能提升百分比对比RTX 2080 Super对比RTX 2080 TiFire Strike / 1080p32%18%Extreme / 1440p63%23%Ultra / 2160p65%30%