Intel 11 日于美国旧金山举行首日 IDF US 2012 技术峰会,会上透露了更多下代微架构 Haswell 处理器的改进,虽然仍基于 22nm 制程,但由于微架构进一步改良,令处理器相较上代功耗有效降低 20x ,性能方面却明显提升,更先进的 Branch Prediction 、更强大 OODE 及 Corresponding Structures 、相较上代新增 Port 6 与 Port 7 提升 Store Address 、 Integer ALU 、 Branch 等运算单元,大幅提升平行运算,并提供了全新的 Intel Advanced Vector Extensions 2 指令集。
据 Intel 表示, Haswell 是首个微架构设计完全覆盖 Tablet 、 Ultrabook 及 Netbook 、 Desktop 、 Workstation 及 Server 各个不同层面,模组化设计能应付不同层面的需要,单颗核心的运算能相较上代 Ivy Bridge 明显提升,同时功耗表现亦明显下降,并在 IDF Day 1 展示了下代 Haswell 处理器 Demo ,预计将于明年第一季正式上市。

Intel IDF US 2012 大会展示了下代 Haswell 处理器 Demo
Front-End 强化升提平行运算
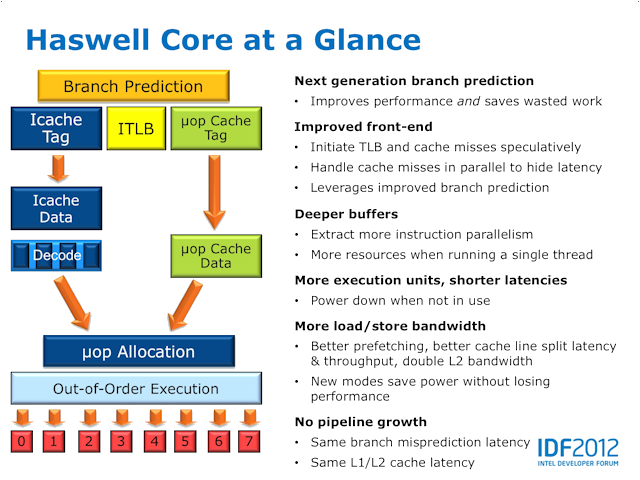
大幅改良 Branch Prediction 以及减少 Cache Misses 的延迟
Haswell 微架构设计主体仍沿自 Sandy Bridge 与 Ivy Bridge ,例如模组化设计及 Interconnect Ring 架构等,但核心 Front-End 的设计则作出大幅修改, Haswell 微架构针对 Branch Prediction 预测分支作出大量强化,此举有助提升运算性能并减少运算週期的浪费。
Haswell 微架构能同时启始 TLB 并平行处理 Cache Misses ,此举可大幅减低资源读取的延迟并提升 Brandch Prediction 的效率﹐拥有更大的 Buffer Sizes 令处理器的平行运算吞吐量大幅提升,同时亦令 Haswell 在运算单线程运算时拥有更佳资源调配。
此外, Haswell 微架构处理器拥有更多 Execution Units ,更低的运算延迟,同时在 Load 及 Store 的 Bandwidth 亦大幅提升, L2 频宽更是上代的一倍,而且 Pipeline 层数却保持不变。
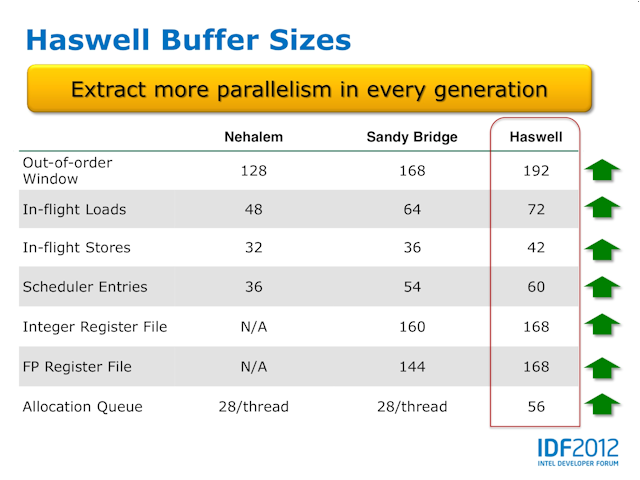
Haswell 微架构在 Buffer Sizes 再进一步提升平行运算能力
图上为 Haswell Buffer Size 数目,可以看到 Intel 在每一代 Core 微架构上,均针对 OOOE Windows 、 In-flight Loads & Stores 、 Scheduler Enteries 、 Integer & FP Register File 的 Buffer 均有所提升,其中升幅最明显的是 Allocation Queue ,过去二代均保持 28 per thread ,今代则大幅提升至 56 per thread ,以上改进均令 Haswell 的平行运算能力大幅提升。
Execution Unit 大幅改良
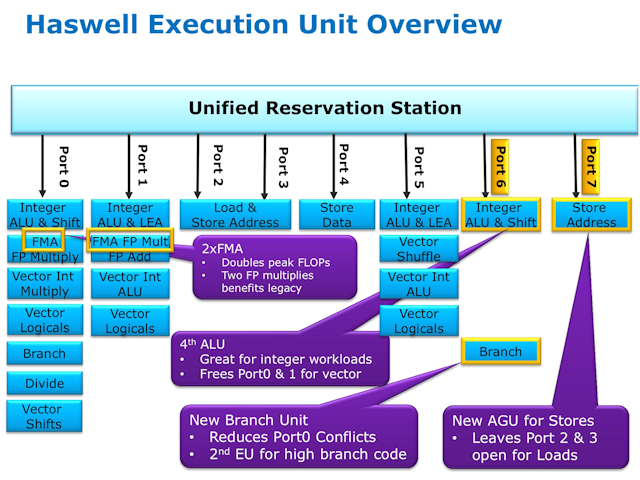
Haswell 不仅 Front-End 作出了强化,同时亦改良了 Execution Unit 的效率,新增了两组 Dispatch Port , Port 6 专门负责 Integer ALU & Shift 、 Port 7 专门处理 Store Address 。
Port 6 作为核心的第四个 ALU ,它是专门针对 Integer 运算而生,并有效减低 Port 0 及 Port 1 的 Vector 运算负担, Port 7 则是 AGU Stores Unit ,分负了 Port 2 及 Port 3 的 Loads 工作负担。
Port 6 同时提供第二组 Branch Unit ,能减少 Port 0 出现冲突的情况,第二组 Branch Unit 针门针对高阶分析程序,有效提升核心的运算性能。
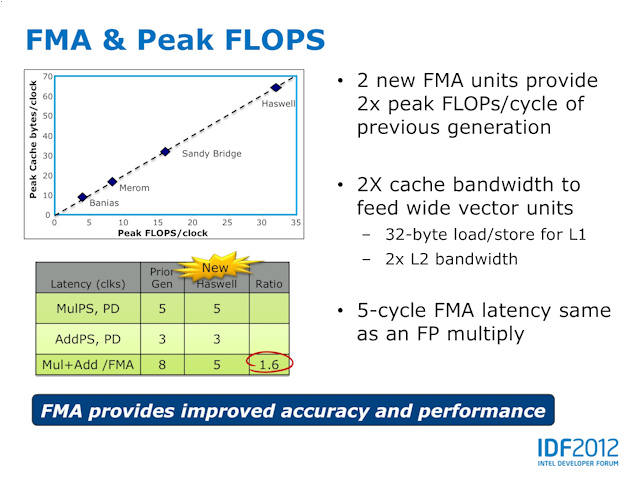
此外, Port 0 和 Port 1 右入了全新的 FMA 运算单元,令 Haswell 的 FMA 运算能力相较 Ivy Bridge 最高提升达 2X ,同时 Cache Bandwidth 亦提升了 2X 以配及 Vector 运算提升。据 Intel 表示,上代 Ivy Bridge 微架构处理器在处理 FMA 运算时,大约需要 8 个 Cycle ,主要是加法和乘法并非平行处理,但全新 Haswell 微架构处理器只需 5 个 Cycle 就能完成 FMA 运算,执行速度与 FP Multiply 运算相同。